Spis zadań w tym module
1. Protokół Iteratora
Aby obiekt mógł być użyty w pętli for, musi implementować dwie metody magiczne: __iter__() (zwraca samą siebie) oraz __next__() (zwraca kolejny element lub zgłasza StopIteration). Iterator "pamięta" swój stan i po przejściu całej sekwencji staje się "wyczerpany".
2. Generatory i słowo yield
Generatory to funkcje, które "pauzują" swoje wykonanie za pomocą słowa yield. W przeciwieństwie do return, yield nie kończy funkcji, lecz wysyła wartość na zewnątrz i czeka na kolejne wywołanie next(). Jest to najprostszy sposób na tworzenie iteratorów.
Implementacji pełnego protokołu iteratora w klasie oraz ręcznego zarządzania stanem pętli i kończeniem sekwencji.
Jako programista odpowiedzialny za optymalizację algorytmów przetwarzania liczb, musisz stworzyć wydajne narzędzie do generowania specyficznych podzbiorów danych. Wyobraź sobie sytuację, w której musisz operować na ogromnych zakresach wartości, ale interesują Cię wyłącznie liczby spełniające konkretne kryteria matematyczne, np. parzystość. Twoim zadaniem jest zaimplementowanie klasy Parzyste, która w pełni realizuje protokół iteratora bez konieczności przechowywania wszystkich wyników w pamięci operacyjnej. Musisz samodzielnie zarządzać stanem pętli poprzez odpowiednią definicję metod magicznych iter oraz next, dbając o poprawne zakończenie sekwencji. Takie podejście pozwala na oszczędność zasobów systemowych, co jest kluczowe w aplikacjach działających pod dużym obciążeniem. Twoja klasa powinna zachowywać się jak inteligentny licznik, który "pamięta" swoją ostatnią pozycję i potrafi wyznaczyć kolejny element na żądanie. Dzięki temu rozwiązaniu, nauczysz się, jak Python pod spodem obsługuje pętle for oraz jak budować własne, zaawansowane struktury sterujące. Gotowe narzędzie będzie doskonałym przykładem na to, jak za pomocą prostych mechanizmów obiektowych można znacząco podnieść wydajność przetwarzania danych.
- Skonstruuj klasę
Parzysterealizującą pełny protokół iteratora w Pythonie. - Zaimplementuj konstruktor
__init__przyjmujący parametrlimitokreślający górną granicę ciągu. - Zdefiniuj metodę magiczną
__iter__, która zgodnie ze standardem musi zwracać obiekt samego siebie (self). - Opracuj metodę
__next__odpowiedzialną za obliczanie i zwracania kolejnych liczb parzystych. - Zastosuj instrukcję
raise StopIteration, aby bezpiecznie i poprawnie zakończyć pętlę po osiągnięciu limitu. - Przechowuj aktualny stan iteratora w atrybucie instancji, zapewniając ciągłość wywołań.
- Przetestuj iterator w pętli
fororaz poprzez wielokrotne wywoływanie funkcjinext(). - Wyjaśnij mechanizm "wyczerpania" iteratora po przejściu całej sekwencji danych.
- W metodzie
__init__zainicjalizujself.limitoraz stan początkowyself.current = 0. - Metoda magiczna
__iter__(self)musi zawsze zwracać obiekt samego siebie (return self). - Wewnątrz
__next__(self)najpierw sprawdź warunek graniczny:if self.current >= self.limit:. - Jeśli limit został osiągnięty, wywołaj przerwanie pętli instrukcją
raise StopIteration. - Oblicz aktualną wartość, zaktualizuj stan wewnętrzny (np.
self.current += 2) i zwróć wynik. - Pamiętaj, że
StopIterationto jedyny poprawny sposób na eleganckie zakończenie pętlifor. - Przetestuj iterator, tworząc obiekt ręcznie i wywołując na nim systemową funkcję
next(). - Zauważ, że po "wyczerpaniu" iterator nie zacznie liczyć od nowa przy kolejnym wywołaniu pętli.
- To zadanie uczy, jak obiekty w Pythonie "pamiętają" swoje aktualne miejsce w sekwencji przetwarzanych danych.
- Sprawdź poprawne działanie iteratora dla limitu równego zero oraz dla wartości ujemnych.
- Wyjaśnij szczegółowo, dlaczego po "wyczerpaniu" iteratora ponowne wywołanie pętli
forna tym samym obiekcie nie wypisuje już żadnych danych. - Opisz techniczne różnice między obiektem iterowalnym (iterable) a samym iteratorem (iterator) w kontekście metody
__iter__. - Omów mechanizm zgłaszania wyjątku
StopIterationi sposób, w jaki standardowa pętlaforreaguje na ten sygnał. - Przeanalizuj korzyści płynące z pełnego, ręcznego zarządzania stanem pętli wewnątrz metod magicznych klasy.
- Zastanów się, w jaki sposób można by zaimplementować metodę
reset(), aby umożliwić wielokrotne użycie tego samego obiektu. - Wnioskuj o realnych oszczędnościach pamięci RAM przy generowaniu bardzo dużych, wirtualnych zbiorów liczb całkowitych na żądanie.
- Porównaj Twój autorski iterator do wbudowanej systemowej funkcji
range()pod kątem funkcjonalności oraz wydajności. - Opisz proces debugowania metod magicznych
__iter__i__next__w nowoczesnych środowiskach programistycznych. - Sprawdź i udokumentuj, czy Twój iterator zachowuje stabilność przy próbie ręcznego pobrania elementu z "wyczerpanego" już źródła.

3. Leniwe wyliczanie (Lazy Evaluation)
Generatory obliczają wartości tylko wtedy, gdy są o nie proszone. Pozwala to na tworzenie sekwencji, które w teorii są nieskończone, a w praktyce zużywają minimalną ilość pamięci RAM (tylko na jeden, aktualny element).
Tworzenia generatorów przy użyciu funkcji i słowa yield oraz zarządzania nieskończonymi pętlami w bezpieczny sposób.
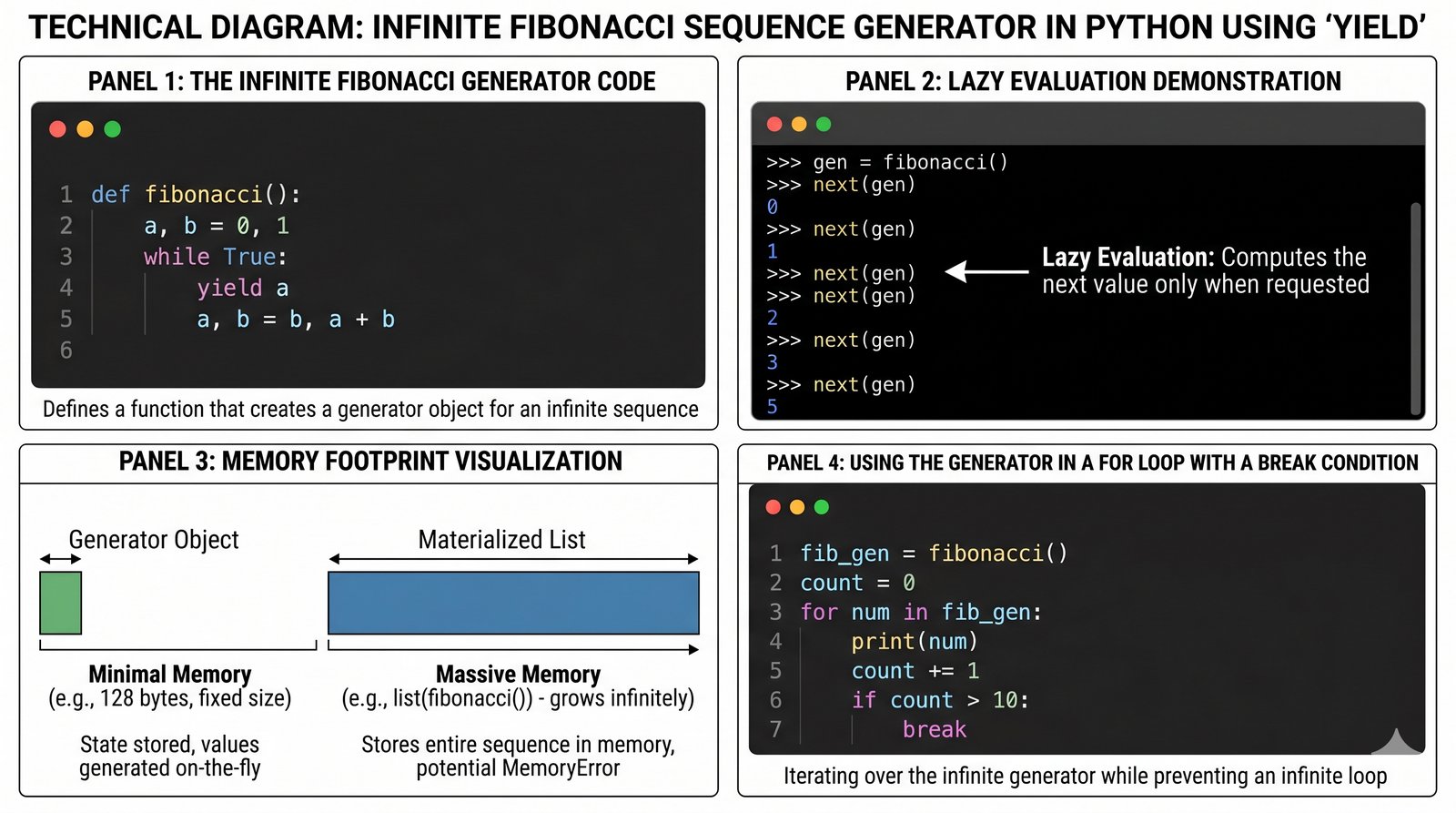
W matematyce i informatyce istnieją ciągi liczbowe, których natura sprawia, że mogą one trwać w nieskończoność, co stanowi ogromne wyzwanie dla tradycyjnych metod przechowywania danych. Twoim zadaniem jest stworzenie generatora ciągu Fibonacciego, który pozwoli na pobieranie kolejnych wyrazów tej słynnej sekwencji bez ryzyka przepełnienia pamięci RAM. Wykorzystaj unikalną cechę generatorów, jaką jest "leniwe" wyliczanie wartości dopiero w momencie, gdy są one faktycznie potrzebne użytkownikowi. Dzięki słowu kluczowemu yield, Twoja funkcja będzie potrafiła pauzować swoje wykonanie i zwracać wynik na żądanie, zachowując jednocześnie swój wewnętrzny stan obliczeniowy. Takie rozwiązanie daje pełną kontrolę programiście korzystającemu z Twojego kodu, który może zdecydować o przerwaniu pobierania danych w dowolnym momencie. Zaimplementuj logikę w taki sposób, aby sumowanie kolejnych elementów odbywało się niezwykle wydajnie za pomocą przypisań wielokrotnych. Jest to doskonała okazja do zrozumienia, dlaczego generatory są uważane za jedno z najpotężniejszych narzędzi w arsenale nowoczesnego programisty Pythona. Gotowy generator będzie potrafił obsłużyć nieskończone pętle obliczeniowe, zużywając przy tym stałą, minimalną ilość zasobów komputera.
- Zdefiniuj funkcję generatora
fibonacci(), wykorzystując słowo kluczoweyield. - Zastosuj nieskończoną pętlę
while Truedo generowania kolejnych wyrazów ciągu bez ograniczeń czasowych. - Wykorzystaj mechanizm przypisania wielokrotnego (
a, b = b, a + b) dla optymalizacji kodu. - Udowodnij "leniwe" działanie generatora, pobierając dane za pomocą funkcji
next(). - Wykorzystaj pętlę
forz warunkiem przerwania (break) do wyświetlenia pierwszych 10 liczb ciągu. - Sprawdź minimalne zużycie pamięci RAM przy generowaniu bardzo dużych wartości matematycznych.
- Zaimplementuj generator tak, aby zaczynał od wartości 0 i 1.
- Wyjaśnij, dlaczego generator nie blokuje wykonywania reszty programu mimo nieskończonej pętli wewnętrznej.
- Funkcja generatora
fibonacci()powinna zawierać nieskończoną pętlę sterującąwhile True:. - Zdefiniuj zmienne pomocnicze
a, b = 0, 1przed rozpoczęciem pętli głównej. - Wewnątrz pętli wykonaj instrukcję
yield a, która "zamrozi" funkcję i wyśle wartość na zewnątrz. - Po wznowieniu pracy wykonaj przejście do kolejnych wyrazów:
a, b = b, a + b. - Utwórz obiekt generatora wywołując funkcję:
gen = fibonacci(). - Pobierz kilka pierwszych wartości ciągu, wywołując wielokrotnie funkcję
next(gen). - Użyj pętli
for i, val in enumerate(gen):z warunkiemif i == 10: breakdla testów. - Zauważ, że generator zajmuje identyczną ilość pamięci niezależnie od tego, jak dużą liczbę aktualnie wylicza.
- Sprawdź, czy Twój generator poprawnie generuje standardowy ciąg zaczynający się od wartości 0 i 1.
- Wyjaśnij w komentarzu, w jaki sposób słowo
yieldpozwala zachować stan lokalny funkcji między wywołaniami.
- Wyjaśnij techniczny mechanizm działania słowa kluczowego
yieldi jego bezpośredni wpływ na "zamrażanie" stanu lokalnego funkcji. - Opisz szczegółowo, dlaczego generator z nieskończoną pętlą
while Truenie zawiesza systemu operacyjnego mimo teoretycznego braku końca. - Omów zalety stosowania mechanizmu przypisania wielokrotnego (
a, b = b, a + b) dla ogólnej czytelności i bezpieczeństwa kodu. - Przeanalizuj pojęcie "Lazy Evaluation" (leniwe wyliczanie) w kontekście generowania skomplikowanych ciągów matematycznych w czasie rzeczywistym.
- Zastanów się nad wydajnością czasową pobierania miliony razy kolejnych wyrazów ciągu Fibonacciego za pomocą Twojego generatora.
- Wnioskuj o minimalnym i stałym narzucie pamięciowym przy pracy z danymi o potencjalnie nieograniczonej długości i precyzji.
- Porównaj generator do klasycznej funkcji rekurencyjnej wyliczającej wyrazy ciągu pod kątem głębokości stosu i ryzyka przepełnienia pamięci.
- Opisz, jak Python sprawnie radzi sobie z operowaniem na bardzo dużych liczbach całkowitych (arbitrary-precision) bezpośrednio w generatorach.
- Sprawdź, czy można użyć Twojego generatora jako bezpośredniego źródła danych dla funkcji agregujących, takich jak
sum()czymax().
4. Przetwarzanie potokowe
Generatory można łączyć w łańcuchy (potoki). Dane "płyną" z jednego generatora do drugiego, będąc filtrowane lub transformowane po drodze, bez tworzenia dużych list tymczasowych w pamięci.
Praktycznego wykorzystania generatorów do obróbki plików tekstowych o rozmiarach przekraczających dostępną pamięć RAM.
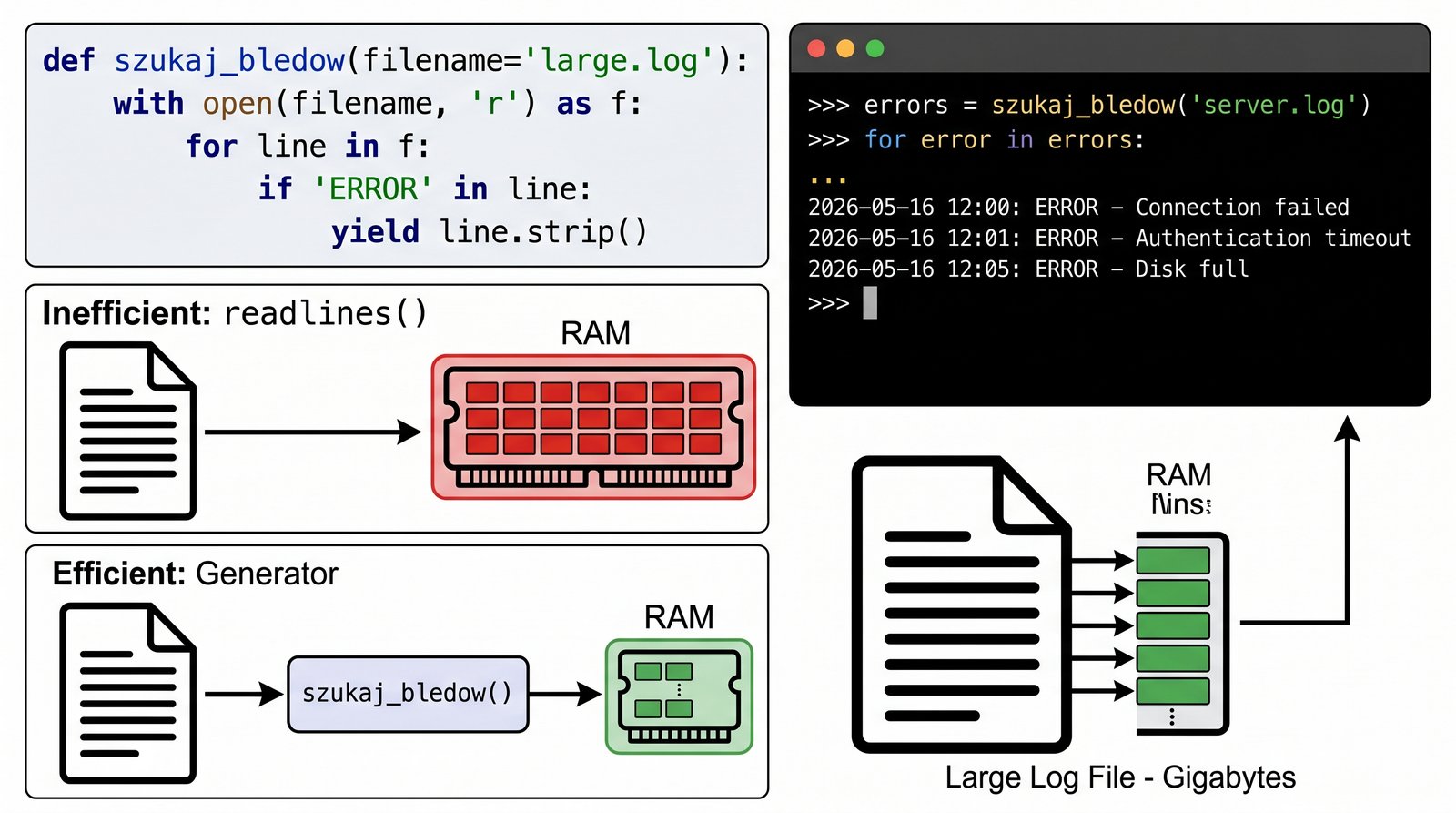
Wyobraź sobie, że stoisz przed wyzwaniem przeanalizowania ogromnych plików logów serwerowych, których rozmiar wielokrotnie przekracza dostępną pamięć operacyjną Twojego komputera. Tradycyjne metody wczytywania całej treści pliku naraz doprowadziłyby do natychmiastowego zawieszenia systemu, dlatego musisz zastosować podejście strumieniowe. Twoim zadaniem jest opracowanie "leniwego" czytnika, który będzie analizował plik linia po linii, wyłapując jedynie krytyczne błędy oznaczone słowem ERROR. Wykorzystaj fakt, że obiekty plików w Pythonie same w sobie działają jak generatory, co pozwala na niezwykle wydajne i bezpieczne przetwarzanie danych tekstowych. Dzięki zastosowaniu słowa yield, Twój program będzie zwracał tylko istotne linie kodu, nie obciążając przy tym procesora niepotrzebnymi operacjami. Taki model pracy jest standardem w profesjonalnej administracji systemami i analizie Big Data, gdzie liczy się każda sekunda i każdy bajt pamięci. Twoje rozwiązanie powinno być odporne na uszkodzenia struktury plików i pozwalać na łatwe filtrowanie informacji w czasie rzeczywistym. Poprawna realizacja tego zadania nauczy Cię, jak budować skalowalne narzędzia diagnostyczne, które poradzą sobie z najbardziej wymagającymi zbiorami danych.
- Opracuj funkcję generatora
szukaj_bledow(), która przyjmuje ścieżkę do pliku tekstowego jako parametr. - Wykorzystaj menedżer kontekstu
with open()do bezpiecznego i wydajnego otwierania plików. - Zastosuj iterację bezpośrednio po obiekcie pliku, wykorzystując jego natywną naturę generatora.
- Zaimplementuj logikę filtrowania, która zwraca (
yield) wyłącznie linie zawierające frazę "ERROR". - Zapewnij ochronę przed przepełnieniem pamięci RAM poprzez przetwarzanie pliku linia po linii (nie używaj
readlines()). - Dodaj do wyniku automatyczne usuwanie białych znaków z końców linii za pomocą metody
.strip(). - Przetestuj działanie czytnika na pliku zawierającym tysiące linii symulowanych logów systemowych.
- Udowodnij, że Twoje rozwiązanie poradzi sobie z plikami o rozmiarach przekraczających gigabajty.
- Wykorzystaj menedżer kontekstu
with open(sciezka, 'r') as f:do bezpiecznej pracy z plikiem. - Iteruj bezpośrednio po obiekcie pliku:
for line in f:(czyta on dane buforowo, linia po linii). - Wewnątrz pętli sprawdzaj obecność słowa kluczowego:
if "ERROR" in line:. - Zwracaj dopasowaną linię za pomocą
yield line.strip(), aby usunąć zbędne białe znaki z końców. - Przetestuj działanie na małym pliku tekstowym, który wcześniej samodzielnie przygotujesz.
- Pamiętaj, że użycie
f.readlines()wczytałoby cały plik do RAM, co przy dużych logach jest błędem. - Zauważ, że mechanizm
yieldpozwala na przetwarzanie danych strumieniowo, bez ich zbędnego buforowania. - To zadanie uczy pisania profesjonalnych skryptów systemowych odpornych na ograniczone zasoby sprzętowe.
- Dodaj prostą obsługę wyjątków (np.
FileNotFoundError) na wypadek braku wskazanego pliku na dysku. - Zastanów się, jak rozbudować generator, aby przyjmował on dynamiczną listę słów do przefiltrowania.
- Wyjaśnij fundamentalną różnicę w zużyciu pamięci RAM między metodą
readlines()a bezpośrednią iteracją po obiekcie pliku. - Opisz strategiczne zalety strumieniowego przetwarzania logów w profesjonalnych systemach klasy Big Data oraz w zaawansowanej administracji serwerami.
- Omów kluczową rolę menedżera kontekstu
with open()w gwarantowaniu absolutnego bezpieczeństwa zasobów systemowych i zamykania uchwytów plików. - Przeanalizuj skuteczność filtrowania danych tekstowych "w locie" bez konieczności tworzenia jakichkolwiek ogromnych list pośrednich w pamięci.
- Zastanów się, w jaki sposób poprawnie obsłużyć błędy kodowania znaków przy czytaniu logów pochodzących z różnych systemów operacyjnych.
- Wnioskuj o wysokiej skalowalności skryptów diagnostycznych, które potrafią bezawaryjnie analizować pliki o rozmiarach wielu gigabajtów.
- Porównaj wydajność Twojego Pythonowego rozwiązania do systemowych narzędzi typu
greppowszechnie dostępnych w systemach Linux. - Opisz sposób rozbudowy generatora o zaawansowaną parametryzację filtrów (np. przekazywanie dynamicznej listy słów kluczowych).
- Sprawdź i opisz stabilność działania Twojego czytnika w dramatycznym przypadku nagłego usunięcia pliku z dysku w trakcie trwania procesu iteracji.
5. Wyrażenia generatorowe
To skrócony zapis generatora w jednej linii. Używamy nawiasów okrągłych (). Działają one identycznie jak "List Comprehensions", ale nie tworzą listy w pamięci.
Łączenia wielu generatorów w łańcuch przetwarzania (Pipeline) oraz rozumienia momentu, w którym faktycznie dochodzi do obliczeń.
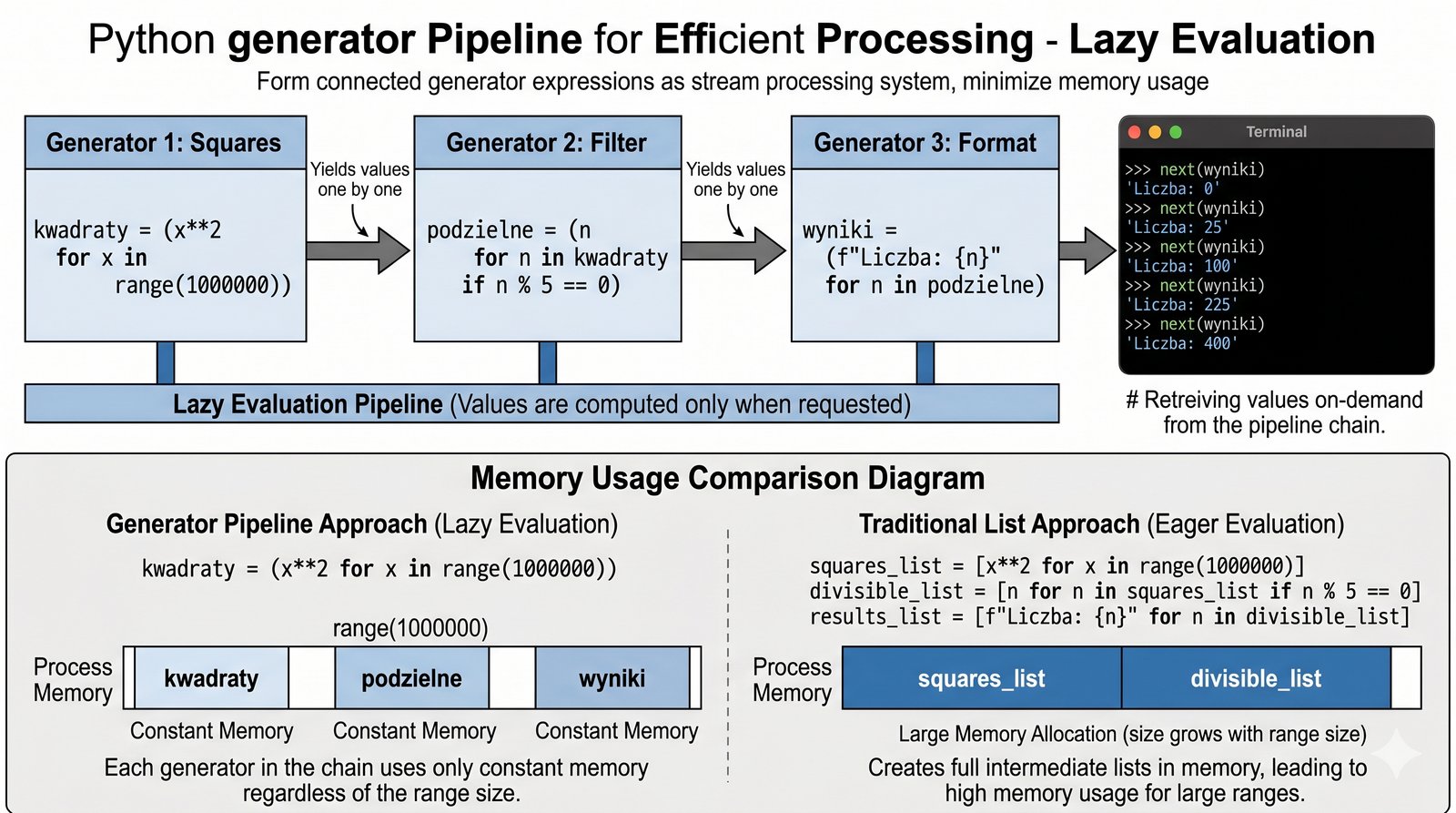
W nowoczesnej inżynierii danych, łączenie wielu etapów przetwarzania w jeden spójny i wydajny potok jest kluczowym elementem optymalizacji procesów analitycznych. Twoim celem jest zaprojektowanie systemu, który automatycznie przekształca i filtruje ogromne zestawy liczb bez tworzenia jakichkolwiek list pośrednich w pamięci komputera. Musisz stworzyć łańcuch generatorów, gdzie wynik pracy jednego z nich staje się natychmiast podstawą do obliczeń dla kolejnego modułu. Wyobraź sobie, że najpierw podnosisz tysiące liczb do kwadratu, a następnie w tym samym strumieniu wybierasz tylko te, które spełniają rygorystyczne kryteria podzielności. Dzięki takiemu podejściu, faktyczne obliczenia zostaną wykonane dopiero w momencie, gdy poprosisz o konkretny wynik końcowy, co jest istotą strategii "lazy evaluation". Takie rozwiązanie pozwala na budowanie niezwykle złożonych procesów transformacji przy zachowaniu minimalnego zużycia zasobów sprzętowych. Twoje zadanie polega na sprawnym połączeniu wyrażeń generatorowych w jedną, płynną całość, która obsłuży dane w sposób modularny i czytelny. Gotowy projekt będzie doskonałym przykładem profesjonalnego wykorzystania mechanizmów strumieniowych w zaawansowanej analityce numerycznej.
- Stwórz wyrażenie generatorowe wyliczające kwadraty liczb z bardzo dużego zakresu (np.
range(1000000)). - Zdefiniuj drugi generator filtrujący (potok), który wybiera z pierwszego tylko liczby podzielne przez 5.
- Skonstruuj trzeci poziom potoku, który formatuje wyniki do postaci czytelnych ciągów tekstowych.
- Wykorzystaj funkcję
next()do ręcznego pobrania kilku próbek danych z końca całego łańcucha. - Zastosuj pętlę
fordo przetworzenia określonej liczby elementów bez generowania całej kolekcji. - Sprawdź czas wykonania operacji, wykazując korzyści płynące z "leniwych" obliczeń (Lazy Evaluation).
- Udowodnij brak tworzenia list pośrednich w pamięci podczas przesyłania danych między generatorami.
- Wyjaśnij, kiedy następuje faktyczne wykonanie obliczeń matematycznych w tak zaprojektowanym systemie.
- Pierwszy etap:
kwadraty = (x**2 for x in range(1000000))(wyrażenie generatorowe). - Drugi etap:
podzielne = (n for n in kwadraty if n % 5 == 0)(filtrowanie potokowe). - Trzeci etap:
wyniki = (f"Liczba: {n}" for n in podzielne)(formatowanie strumieniowe). - Wyświetl próbkę danych:
for _ in range(5): print(next(wyniki)). - Zauważ, że do momentu jawnego poproszenia o wynik w pętli, żadne obliczenia nie zostaną wykonane.
- Ten mechanizm nazywamy łańcuchowaniem (chaining) generatorów i jest on podstawą przetwarzania potokowego.
- Porównaj natychmiastowy czas "stworzenia" potoku z czasem potrzebnym na pobranie konkretnych wyników.
- Wyjaśnij, w jaki sposób potoki pozwalają budować bardzo modularne i czytelne procesy analityczne.
- Sprawdź stabilność systemu, gdy jeden z generatorów w środku łańcucha szybciej wyczerpie swoje źródło danych.
- Zauważ, że każde kolejne wyrażenie generatorowe zużywa jedynie minimalną i stałą ilość pamięci operacyjnej.
- Wyjaśnij, dlaczego łączenie wielu generatorów w potoki jest znacznie bardziej modularne i czytelne niż pisanie monolitycznych pętli sterujących.
- Opisz precyzyjnie moment, w którym faktycznie dochodzi do wykonania skomplikowanych obliczeń matematycznych w tak zaprojektowanym łańcuchu.
- Omów korzyści płynące z "łańcuchowania" (chaining) wielu operacji transformacji i filtrowania dużych zbiorów danych numerycznych.
- Przeanalizuj wpływ wyrażeń generatorowych na ogólną czystość i zwięzłość kodu źródłowego dzięki zastosowaniu składni jednolinijkowej.
- Zastanów się, czy kolejność elementów w potoku (np. najpierw filtrowanie, potem ciężkie obliczenia) ma kluczowy wpływ na wydajność całego systemu.
- Wnioskuj o wymiernych oszczędnościach procesora i pamięci RAM dzięki unikaniu alokacji jakichkolwiek dużych kolekcji tymczasowych.
- Porównaj potoki generatorowe w Pythonie do podobnych technologii, takich jak
Streamsw Javie czyLINQw języku C#. - Opisz, w jaki sposób zareaguje cały potok, gdy jedno ze źródeł danych w środku łańcucha ulegnie niespodziewanemu wyczerpaniu.
- Sprawdź, czy potoki można łatwo debugować w trakcie pracy, podglądając stan pośredni danych przepływających między poszczególnymi ogniwami.
6. Metoda send()
Generatory mogą nie tylko wysyłać dane na zewnątrz, ale też odbierać je w trakcie pracy. Służy do tego metoda send(), która pozwala na interakcję z działającym generatorem.
7. yield from
Słowo kluczowe yield from pozwala na delegowanie pracy do innego generatora. Jest to niezwykle przydatne przy rekurencyjnym przeszukiwaniu np. folderów na dysku.
8. Moduł itertools
Biblioteka standardowa zawiera moduł itertools z gotowymi funkcjami do pracy na iteratorach, takimi jak cycle() (nieskończone powtarzanie) czy chain() (łączenie kilku zbiorów).
9. Wydajność RAM
Dla 10 milionów liczb lista zajmuje około 400 MB RAM, natomiast generator zaledwie 128 bajtów. To sprawia, że generatory są kluczowe w systemach Big Data.
10. Podsumowanie strumieni
Wiesz już, jak pisać kod "leniwy", który oszczędza zasoby komputera. Potrafisz przetwarzać gigantyczne pliki i tworzyć nieskończone sekwencje danych. Jesteś gotowy do pracy z profesjonalnymi strumieniami danych.
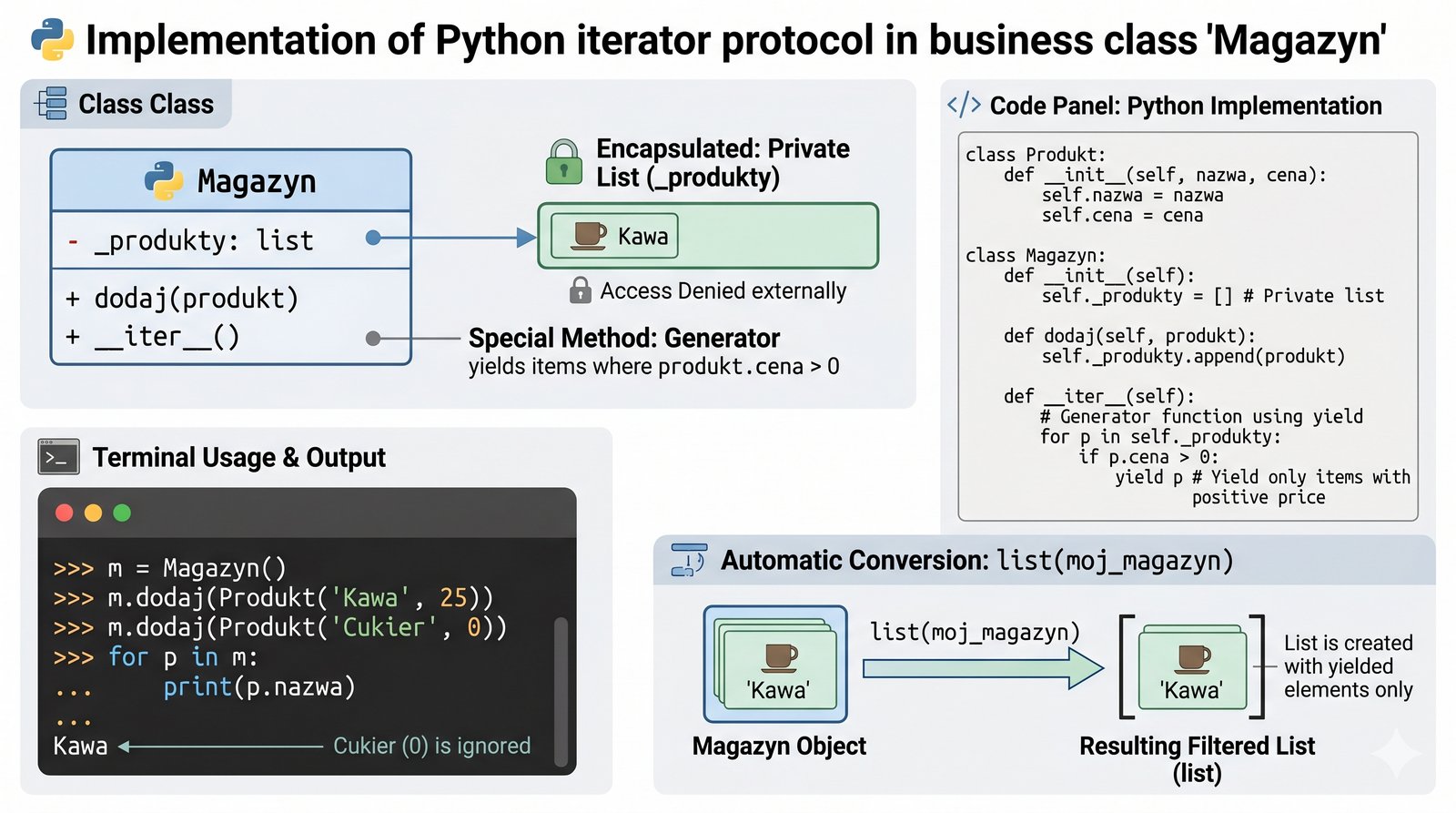
Integracji protokołu iteratora z klasami biznesowymi przy użyciu generatorów, co pozwala na eleganckie przeglądanie kolekcji obiektów.
Podczas projektowania systemów zarządzania zasobami, takich jak magazyny czy inwentarze, niezwykle ważne jest zapewnienie eleganckiego i bezpiecznego dostępu do zgromadzonych obiektów. Twoim zadaniem jest wzbogacenie klasy Magazyn o pełną obsługę protokołu iteracji, co pozwoli na przeglądanie asortymentu za pomocą prostych i naturalnych pętli for. Zamiast udostępniać bezpośrednio wewnętrzną listę produktów, zaimplementuj metodę magiczną iter, która za pomocą mechanizmu yield będzie zwracała kolejne elementy kolekcji. Takie podejście znacząco poprawia hermetyzację Twojego kodu, ponieważ pozwala na wprowadzenie dodatkowej logiki filtrowania już na poziomie samego procesu iteracji. Możesz na przykład zdecydować, aby darmowe produkty były automatycznie pomijane podczas standardowego przeglądu stanów magazynowych. Programista korzystający z Twojej klasy zyska dzięki temu niezwykle intuicyjny interfejs, który ukrywa skomplikowaną strukturę danych pod spodem. Jest to jedna z najlepszych praktyk projektowych, która sprawia, że obiekty biznesowe stają się naturalnym elementem ekosystemu języka Python. Poprawna realizacja tego zadania pokaże Ci, jak harmonijnie łączyć logikę biznesową z zaawansowanymi mechanizmami iteracyjnymi.
- Skonstruuj klasę
Magazynzarządzającą wewnętrzną kolekcją obiektów produktów. - Zaimplementuj metodę magiczną
__iter__, przekształcając ją w generator za pomocą słowayield. - Zapewnij bezpieczny dostęp do danych poprzez iterację po prywatnej liście
_produkty. - Wprowadź wewnątrz metody
__iter__logikę biznesową, np. pomijanie produktów oznaczonych jako archiwalne. - Dodaj możliwość iterowania bezpośrednio po instancji klasy
Magazynw pętlifor item in magazyn:. - Wykorzystaj funkcję
yielddo zwracania sformatowanych opisów produktów zamiast surowych obiektów. - Przetestuj hermetyzację, sprawdzając, czy użytkownik może przeglądać dane bez dostępu do samej listy.
- Wyjaśnij, jak użycie generatora w
__iter__ułatwia późniejszą modyfikację sposobu filtrowania zasobów.
- Wewnątrz klasy
Magazynzdefiniuj metodę magicznądef __iter__(self):. - Zaimplementuj w niej pętlę iterującą po prywatnej kolekcji
self._produkty. - Dodaj filtr biznesowy bezpośrednio w pętli:
if produkt.cena > 0: yield produkt. - Dzięki tej metodzie, wywołanie
for p in moj_magazyn:zacznie działać w sposób automatyczny. - Zauważ, że obecność słowa
yieldwewnątrz__iter__sprawia, że zwraca ona gotowy iterator. - To zadanie uczy, jak sprawić, by własne obiekty biznesowe integrowały się ze standardową składnią Pythona.
- Przetestuj hermetyzację: upewnij się, że nie udostępniasz bezpośredniego dostępu do listy produktów na zewnątrz.
- Sprawdź, czy możesz użyć
list(moj_magazyn)– Python zbuduje ją automatycznie korzystając z Twojego iteratora. - Wyjaśnij przewagę stosowania
yieldnad tworzeniem i zwracaniem pełnej kopii listy wszystkich zasobów. - Dodaj do klasy metodę
__len__, aby w pełni dopełnić protokół kolekcji i umożliwić sprawdzanie rozmiaru.
- Wyjaśnij szczegółowo, w jaki sposób udostępnienie iteratora zamiast pełnej listy poprawia hermetyzację i szczelność Twojej klasy biznesowej.
- Opisz techniczne zalety stosowania mechanizmu
yieldbezpośrednio wewnątrz metody__iter__dla czystości implementacji. - Omów możliwość całkowitego ukrycia wewnętrznej struktury danych (np. zmiana listy na słownik) bez żadnego wpływu na kod korzystający z klasy.
- Przeanalizuj mechanizm automatycznego wsparcia dla funkcji systemowych
list()oraztuple()dzięki poprawnej implementacji protokołu iteracji. - Zastanów się nad dodaniem zaawansowanych filtrów biznesowych (np. ukrywanie produktów archiwalnych) bezpośrednio w samym procesie iteracji.
- Wnioskuj o profesjonalizmie interfejsu klasy, która integruje się w sposób absolutnie naturalny ze standardową składnią pętli
for. - Porównaj wydajność zwracania generatora "w locie" do zwracania pełnej kopii całej kolekcji danych (tzw. deep copy).
- Opisz kluczową rolę metody
__len__w dopełnianiu interfejsu kolekcji i umożliwianiu szybkiego sprawdzenia aktualnego rozmiaru magazynu. - Sprawdź, czy wielokrotna iteracja po obiekcie magazynu wymaga od programisty każdorazowego tworzenia nowego obiektu generatora.