Spis zadań w tym module
1. Co to jest wyjątek?
Wyjątek to specjalny obiekt, który jest zgłaszany (wyrzucany) w momencie wystąpienia błędu. W programowaniu obiektowym błędy nie są tylko napisami w konsoli – są instancjami klas, które dziedziczą po wspólnej bazie Exception.
2. Anatomia obsługi (try-except)
Blok try zawiera kod "ryzykowny". Jeśli w nim wystąpi błąd, Python przerywa jego działanie i szuka pasującego bloku except. Dodatkowo możemy użyć else (gdy błędu brak) oraz finally (wykonuje się zawsze, np. do zamykania plików).
Stosowania kompletnej konstrukcji obsługi błędów oraz rozumienia roli poszczególnych bloków w cyklu życia programu.
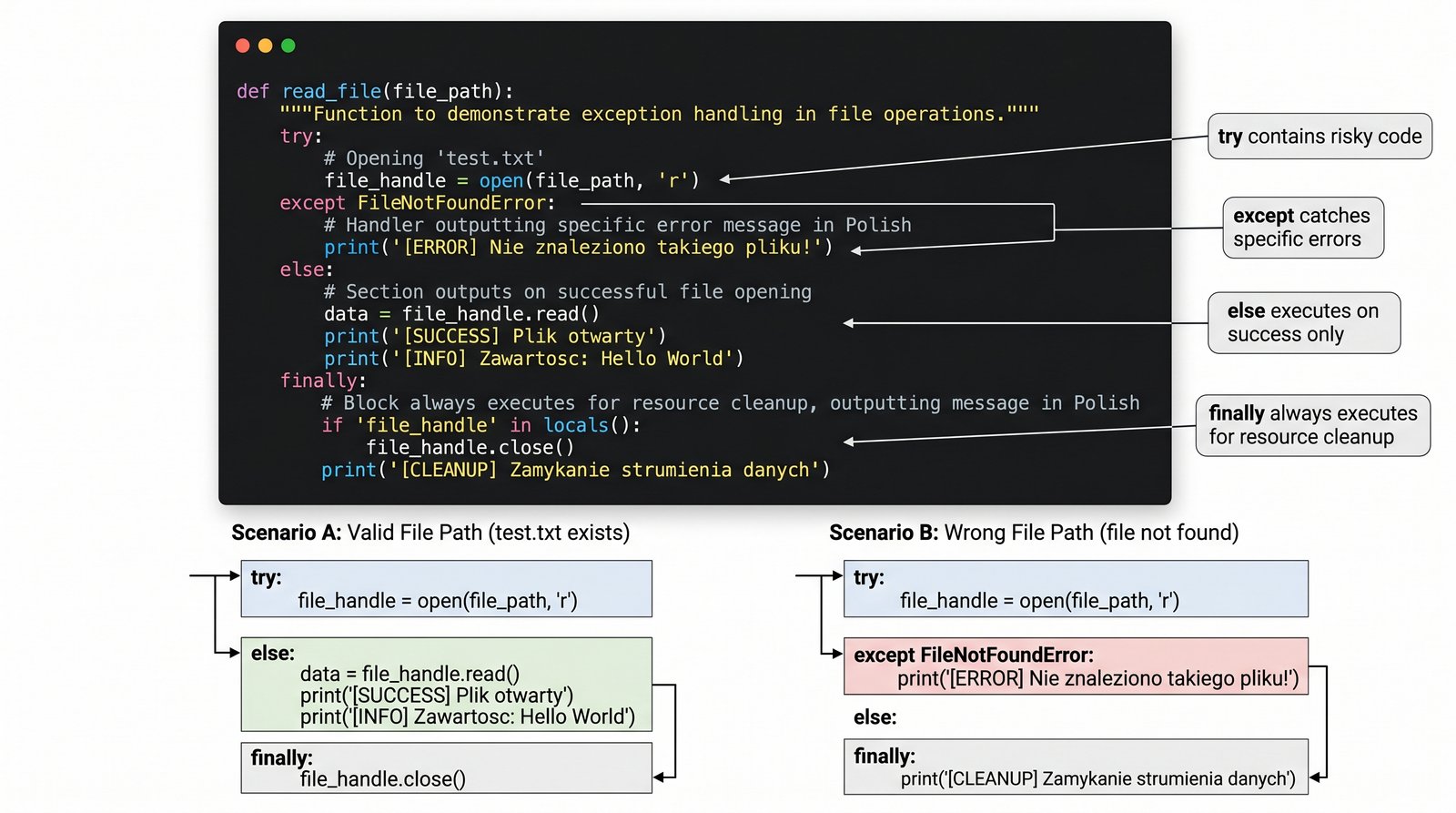
Jako programista odpowiedzialny za budowę bezpiecznych systemów dostępu do danych, musisz przygotować aplikację, która potrafi elegancko radzić sobie z nieprzewidywalnymi problemami systemowymi. Twoim zadaniem jest stworzenie modułu do obsługi plików, który wykorzystuje pełną konstrukcję try-except-else-finally do zarządzania zasobami. Wyobraź sobie sytuację, w której użytkownik podaje błędną ścieżkę do pliku lub próbuje otworzyć dokument, do którego nie posiada odpowiednich uprawnień administracyjnych. Musisz zaprojektować mechanizm, który w przypadku sukcesu wyświetli treść pliku, a w razie porażki precyzyjnie poinformuje o naturze napotkanego problemu. Kluczowym elementem zadania jest zapewnienie, aby wszystkie otwarte strumienie danych zostały bezpiecznie zamknięte, niezależnie od tego, czy operacja zakończyła się powodzeniem, czy krytycznym błędem. Takie podejście gwarantuje stabilność systemu i zapobiega wyciekom pamięci, co jest absolutnie niezbędne w profesjonalnych rozwiązaniach serwerowych. Twoje rozwiązanie pokaże, jak za pomocą strukturalnej obsługi wyjątków można budować oprogramowanie odporne na błędy użytkownika i kaprysy systemu operacyjnego. Gotowy moduł będzie stanowił wzorcowy przykład poprawnej kontroli przepływu w sytuacjach kryzysowych.
- Zaimplementuj kompletny mechanizm obsługi błędów przy użyciu bloków
try,except,elseorazfinally. - Skonstruuj logikę bezpiecznego otwierania pliku tekstowego, uwzględniając wyjątek
FileNotFoundError. - Dodaj blok
exceptdla ogólnych błędów wejścia/wyjścia (IOError), aby zwiększyć odporność programu. - Wykorzystaj sekcję
elsedo wykonania operacji na danych wyłącznie w przypadku pełnego sukcesu wczytywania. - Zdefiniuj blok
finally, który zagwarantuje zamknięcie wszystkich otwartych zasobów (plików) niezależnie od wyniku. - Wyświetl sformatowane komunikaty diagnostyczne w każdej sekcji bloku obsługi błędów.
- Przetestuj działanie modułu dla pliku istniejącego oraz dla błędnej ścieżki dostępu.
- Wyjaśnij, dlaczego instrukcja
elsejest uważana za bardziej czytelną niż umieszczanie całego kodu wewnątrz blokutry.
- Wewnątrz bloku
tryspróbuj otworzyć plik tekstowy za pomocą instrukcjiopen(nazwa). - Obsłuż błąd
FileNotFoundError(brak pliku) orazPermissionError(brak uprawnień). - Wykorzystaj sekcję
elsedo wypisania treści – ten kod wykona się tylko, gdy nie wystąpi żaden wyjątek. - W bloku
finallyzagwarantuj zamknięcie pliku:if 'f' in locals(): f.close(). - Przetestuj scenariusz sukcesu (plik istnieje na dysku) oraz porażki (podanie błędnej lub pustej nazwy).
- Pamiętaj, że sekcja
finallywykona się zawsze, nawet jeśli w blokuexceptużyjeszreturn. - To zadanie uczy poprawnego i profesjonalnego zarządzania cyklem życia zasobów zewnętrznych w systemie.
- Upewnij się, że komunikaty diagnostyczne w
exceptsą precyzyjne i pomocne dla końcowego użytkownika. - Wyjaśnij, w jaki sposób
elsepomaga odseparować główną logikę sukcesu od technicznej obsługi błędów. - Zastanów się, czy w nowoczesnym Pythonie zamiast
finallynie lepiej zastosować menedżerawith.
- Wyjaśnij szczegółowo, dlaczego operację
file.close()należy bezwzględnie umieszczać w blokufinally, a nie na samym końcu sekcjitry. - Opisz rolę sekcji
elsew eleganckim oddzielaniu głównej logiki sukcesu programu od technicznego kodu obsługi błędów. - Omów mechanizm precyzyjnego przechwytywania konkretnych wyjątków systemowych, takich jak
FileNotFoundErrorczyPermissionError. - Przeanalizuj zachowanie bloku
finallyw specyficznych sytuacjach, gdy w blokuexceptzostanie użyta instrukcjareturn. - Zastanów się, czy w nowoczesnym Pythonie 3.x stosowanie menedżera kontekstu (instrukcja
with) jest lepszą praktyką niż ręczne używaniefinally. - Wnioskuj o poprawie stabilności aplikacji serwerowych dzięki gwarantowanemu i terminowemu zwalnianiu cennych zasobów systemowych.
- Porównaj czytelność kodu z wieloma wyspecjalizowanymi blokami
exceptdo kodu z jednym ogólnym blokiem przechwytującym klasęException. - Opisz, w jaki sposób sformatowane komunikaty diagnostyczne w sekcji
exceptznacząco ułatwiają pracę administratorom i deweloperom. - Sprawdź doświadczalnie, czy blok
elsewykona się w przypadku, gdy wyjątek zostanie rzucony, ale nie zostanie obsłużony w danym blokutry.
3. Własne klasy wyjątków
Standardowe błędy jak ValueError są zbyt ogólne dla logiki biznesowej. Tworząc własną klasę dziedziczącą po Exception, sprawiasz, że Twój kod jest bardziej czytelny i łatwiejszy do debugowania przez innych programistów.
Tworzenia własnych typów błędów specyficznych dla domeny problemu oraz przekazywania do nich dodatkowych informacji (atrybutów).
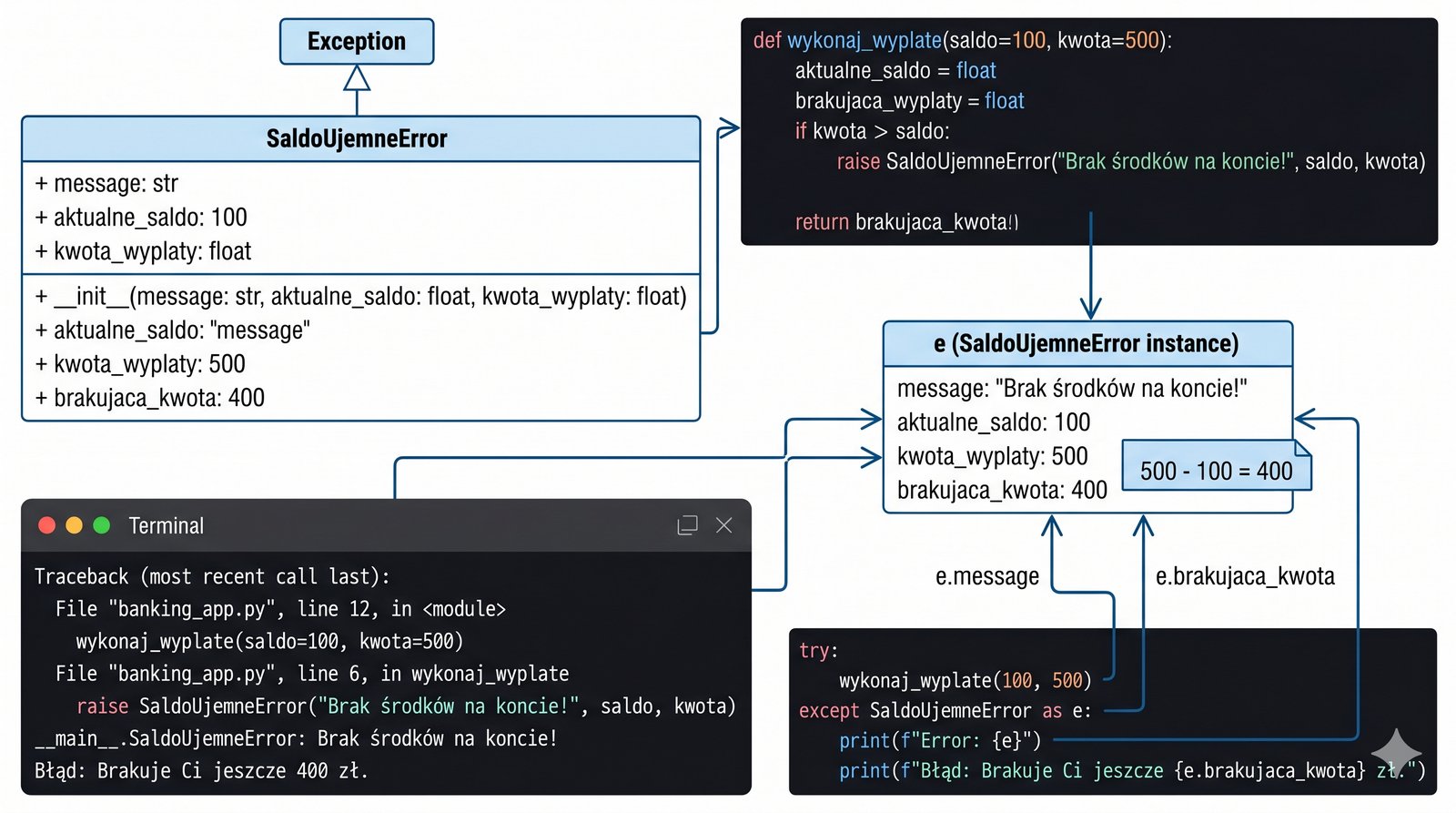
W profesjonalnym programowaniu obiektowym standardowe komunikaty o błędach są często zbyt ogólne, aby precyzyjnie opisać specyficzne problemy wynikające z logiki biznesowej Twojej aplikacji. Twoim wyzwaniem jest zaprojektowanie zaawansowanego systemu obsługi kont bankowych, który korzysta z autorskich klas wyjątków do sygnalizowania nietypowych sytuacji finansowych. Musisz stworzyć klasę SaldoUjemneError, która nie tylko przekaże informację o niepowodzeniu wypłaty, ale również dostarczy precyzyjnych danych o brakującej kwocie środków. Dzięki temu, programista korzystający z Twojego modułu będzie mógł w łatwy sposób zareagować na błąd, wyświetlając użytkownikowi spersonalizowaną sugestię doładowania konta. Wykorzystanie dziedziczenia po bazowej klasie Exception pozwoli Ci na zachowanie wszystkich standardowych funkcjonalności błędów Pythona przy jednoczesnym dodaniu własnych, unikalnych atrybutów. Takie podejście znacząco podnosi czytelność kodu i ułatwia późniejsze debugowanie skomplikowanych procesów transakcyjnych. Pamiętaj, że dobrze zdefiniowane wyjątki są formą dokumentacji technicznej, która mówi innym deweloperom, jakie sytuacje brzegowe przewidziałeś w swoim projekcie. Gotowy system pokaże, jak za pomocą własnych typów błędów można budować niezwykle precyzyjne i profesjonalne interfejsy programistyczne.
- Utwórz autorską klasę wyjątku
SaldoUjemneError, dziedziczącą po wbudowanej klasieException. - Rozszerz klasę wyjątku o specyficzne atrybuty, takie jak
aktualne_saldoorazkwota_wyplaty. - Zaimplementuj metodę
__init__, aby poprawnie inicjalizować komunikat o błędzie wraz z dodatkowymi danymi. - Opracuj funkcję
wykonaj_wyplate(), która rzuca (raise) Twój wyjątek w przypadku braku środków. - Zaimplementuj blok
try...except, przechwytujący wyłącznie błądSaldoUjemneError. - Wykorzystaj dane zawarte w obiekcie wyjątku (np. brakującą kwotę) do wyświetlenia czytelnej sugestii dla użytkownika.
- Przetestuj system, wyzwalając błąd przy próbie wypłaty kwoty przekraczającej stan konta.
- Uzasadnij, jak stosowanie własnych typów wyjątków wpływa na profesjonalizm i łatwość utrzymania kodu.
- Stwórz własną klasę błędu:
class SaldoUjemneError(Exception):dziedziczącą po bazie. - Dodaj konstruktor
__init__(self, message, brakujaca_kwota)do swojej nowej klasy. - Pamiętaj o wywołaniu
super().__init__(message), aby zachować standardowy mechanizm opisów błędów. - W metodzie wypłaty wykonaj test:
if kwota > saldo: raise SaldoUjemneError(...). - W bloku
except SaldoUjemneError as e:odczytaj wartość z atrybutue.brakujaca_kwota. - To zadanie uczy, jak dostarczać precyzyjną informację zwrotną o błędach biznesowych w Twojej aplikacji.
- Przetestuj zgłaszanie wyjątku z różnymi parametrami, aby sprawdzić poprawność wyliczania brakujących środków.
- Zauważ, że autorski wyjątek pozwala na bardzo specyficzne filtrowanie błędów w rozbudowanych blokach
except. - Wyjaśnij, jak dodatkowe atrybuty wyjątku ułatwiają budowanie inteligentnych interfejsów (np. graficznych okien GUI).
- Zastanów się, czy Twoje klasy błędów powinny dziedziczyć bezpośrednio po
Exceptionczy poBaseException.
- Wyjaśnij kluczowe zalety posiadania wielu specyficznych klas wyjątków biznesowych (np.
WrongPasswordError) zamiast jednego ogólnego błędu. - Opisz techniczny proces przekazywania dodatkowych atrybutów technicznych (np. brakująca kwota) bezpośrednio do obiektu własnego wyjątku.
- Omów znaczenie dziedziczenia po bazowej klasie
Exceptiondla zachowania standardowej funkcjonalności raportowania błędów w Pythonie. - Przeanalizuj rolę metody
__init__w inicjalizacji spersonalizowanych i pomocnych komunikatów diagnostycznych dla końcowego użytkownika. - Zastanów się, w jaki sposób własne klasy wyjątków mogą służyć jako forma czytelnej dokumentacji technicznej dla innych programistów w zespole.
- Wnioskuj o ułatwieniu budowy inteligentnych interfejsów (np. GUI), które reagują w unikalny sposób na każdy specyficzny typ błędu biznesowego.
- Porównaj rzucanie wyjątków (
raise) do tradycyjnego zwracania kodów błędów (np.-1lubNone) przez funkcje systemowe. - Opisz, jak selektywne przechwytywanie autorskich błędów w blokach
exceptskutecznie zapobiega przypadkowemu wyciszaniu błędów systemowych. - Sprawdź doświadczalnie, czy Twoja autorska klasa wyjątku poprawnie wyświetla pełny Traceback z uwzględnieniem wszystkich przekazanych parametrów inicjalizacji.
4. Łańcuchowanie (Exception Chaining)
Czasami jeden błąd powoduje inny (np. błąd bazy danych powoduje błąd aplikacji). Za pomocą raise ... from ... możemy zachować informację o pierwotnej przyczynie, co jest nieocenione przy analizie logów.
Zasady "łapania i puszczania dalej" (re-raising) wyjątków w celu logowania problemów przy jednoczesnym informowaniu wyższych warstw aplikacji.
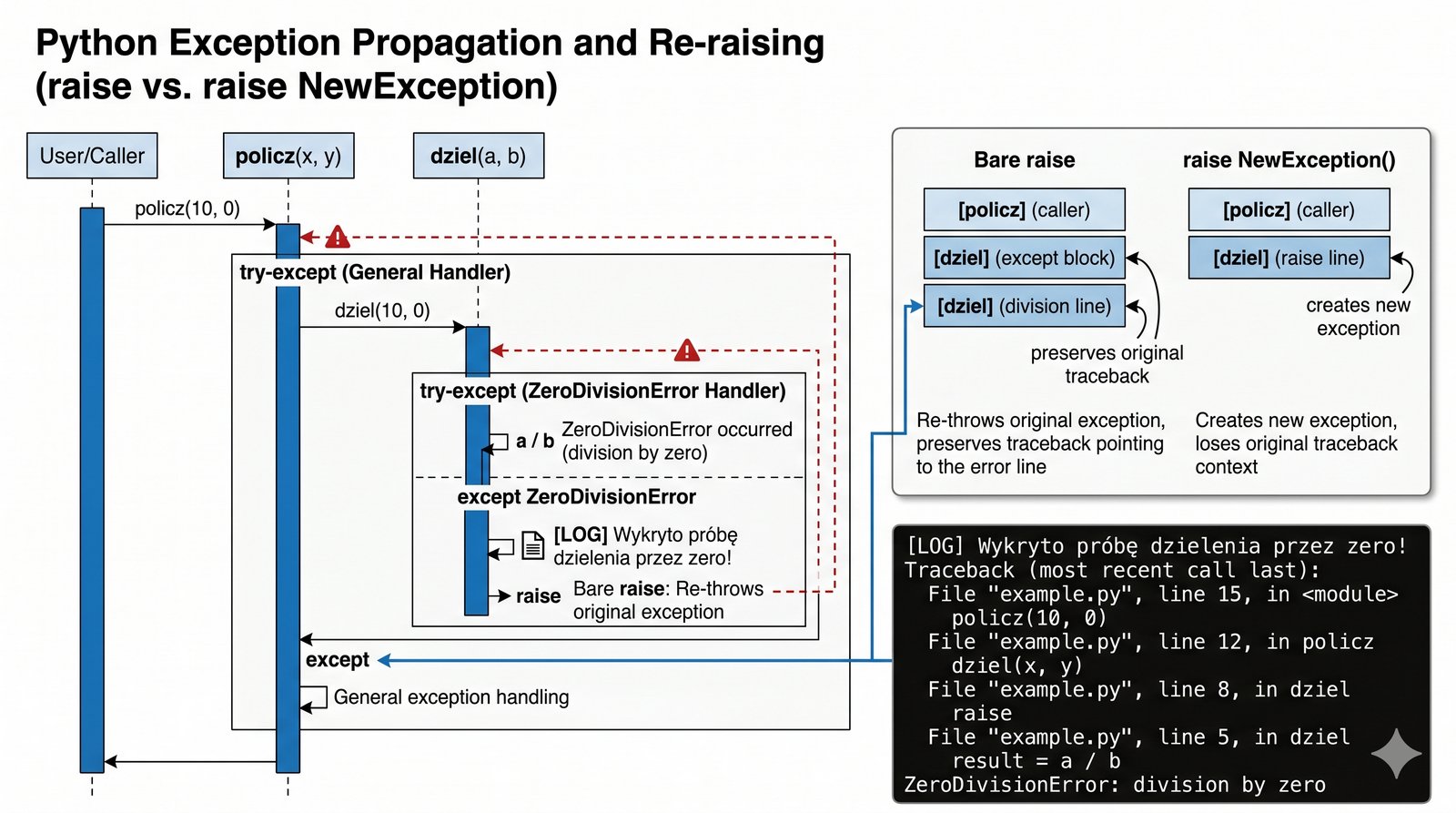
Często w architekturze wielowarstwowych systemów informatycznych zachodzi potrzeba przechwycenia błędu na niskim poziomie tylko po to, aby go udokumentować, a następnie przekazać dalej do głównego modułu sterującego. Twoim zadaniem jest zaimplementowanie mechanizmu propagacji wyjątków podczas wykonywania skomplikowanych operacji matematycznych, takich jak dzielenie przez zero. Musisz zaprojektować funkcję, która w momencie wystąpienia błędu automatycznie wygeneruje wpis w logach systemowych, informując administratora o zaistniałym incydencie. Następnie, za pomocą słowa kluczowego raise, błąd powinien zostać ponownie zgłoszony, aby interfejs użytkownika mógł wyświetlić stosowny komunikat ostrzegawczy. Takie podejście pozwala na oddzielenie logiki diagnostycznej od logiki prezentacji danych, co jest kluczowe dla zachowania porządku w dużych projektach. Dzięki temu zachowasz pełną informację o miejscu powstania problemu (Traceback), co znacząco ułatwi późniejszą analizę przyczyn awarii przez zespół techniczny. Jest to doskonała okazja do zrozumienia, jak błędy "wędrują" przez kolejne warstwy aplikacji, aż do momentu ich ostatecznego rozwiązania. Poprawna realizacja tego zadania pokaże Twoją biegłość w projektowaniu systemów o wysokim stopniu niezawodności i przejrzystości diagnostycznej.
- Skonstruuj funkcję matematyczną (np. dzielenie), która jest podatna na wystąpienie błędu
ZeroDivisionError. - Otocz wywołanie operacji blokiem
try...exceptw celu przechwycenia wyjątku na niskim poziomie. - Zaimplementuj wewnątrz bloku obsługi operację logowania zdarzenia (np.
print("[LOG] Wykryto dzielenie przez zero")). - Wykorzystaj instrukcję
raise(bez parametrów), aby "puścić" błąd dalej do wyższych warstw aplikacji. - Udowodnij, że ponowne zgłoszenie błędu zachowuje pełną informację o miejscu jego pierwotnego wystąpienia (Traceback).
- Przetestuj propagację błędu w architekturze wielopoziomowej (funkcja wywołuje funkcję).
- Wyjaśnij różnicę między
raisearaise e(gdzieeto złapany wyjątek) w kontekście śledzenia stosu wywołań. - Wskaż praktyczne zastosowanie tej techniki w systemach wymagających jednoczesnego logowania i raportowania awarii.
- Skonstruuj funkcję
dziel(a, b), która aktywnie obsługuje wyjątekZeroDivisionError. - Wewnątrz bloku
exceptdodaj instrukcjęprint, która symuluje logowanie błędu do logów systemowych. - Na samym końcu tego bloku umieść słowo kluczowe
raisebez podawania żadnego obiektu błędu. - Wywołaj tę funkcję wewnątrz innej metody, która również posiada własny mechanizm przechwytywania wyjątków.
- Zaobserwuj w konsoli, że
Tracebackpoprawnie wskazuje na linię dzielenia, a nie na miejsce ponownego zgłoszenia. - To zadanie uczy, jak bezpiecznie "podglądać" błędy na niskim poziomie bez ich ostatecznego wyciszania.
- Przetestuj zachowanie pełnego stosu wywołań przy wielopoziomowej propagacji błędu przez kolejne moduły.
- Wyjaśnij różnicę między samym
raisearaise ew kontekście zachowania historii wywołań. - Zastanów się, dlaczego logowanie błędów na niskim poziomie jest krytyczne w architekturze mikroserwisów.
- Wskaż, czy logi powinny trafiać bezpośrednio na ekran, czy do dedykowanego systemu zbierania zdarzeń.
- Wyjaśnij różnicę między wywołaniem samego
raise(puste) a ponownym rzuceniem błędu przezraise ZeroDivisionError()wewnątrz bloku obsługi. - Opisz, jak ponowne zgłoszenie błędu pozwala na jednoczesne logowanie incydentu w systemie i informowanie wyższych warstw aplikacji o problemie.
- Omów znaczenie bezwzględnego zachowania pełnej historii wywołań (Traceback) przy celowej propagacji wyjątków przez kolejne moduły programu.
- Przeanalizuj architekturę wielowarstwową, w której błędy techniczne "wędrują" od warstwy dostępu do danych aż do warstwy prezentacji użytkownika.
- Zastanów się, dlaczego logowanie błędów na niskim poziomie jest krytyczne dla poprawnej diagnostyki w rozproszonych środowiskach mikroserwisowych.
- Wnioskuj o przejrzystości diagnostycznej całego systemu, który skutecznie separuje kod logowania od kodu wyświetlania ostrzeżeń wizualnych.
- Porównaj mechanizm propagacji wyjątków do tradycyjnego przekazywania informacji o błędach w parametrach wyjściowych funkcji.
- Opisz sposób, w jaki puste
raisebez argumentu pozwala uniknąć zniekształcenia informacji o oryginalnym miejscu wystąpienia awarii. - Sprawdź zachowanie stosu wywołań w sytuacji, gdy błąd jest propagowany przez więcej niż trzy poziomy zagnieżdżenia różnych funkcji.
5. EAFP vs LBYL
W Pythonie obowiązuje filozofia EAFP (Easier to Ask for Forgiveness than Permission). Oznacza to, że zamiast sprawdzać if przed każdą operacją, lepiej "spróbować" ją wykonać i obsłużyć ewentualny błąd.
Mapowania wyjątków niskopoziomowych na błędy wysokopoziomowe przy zachowaniu pełnej historii problemu (root cause).
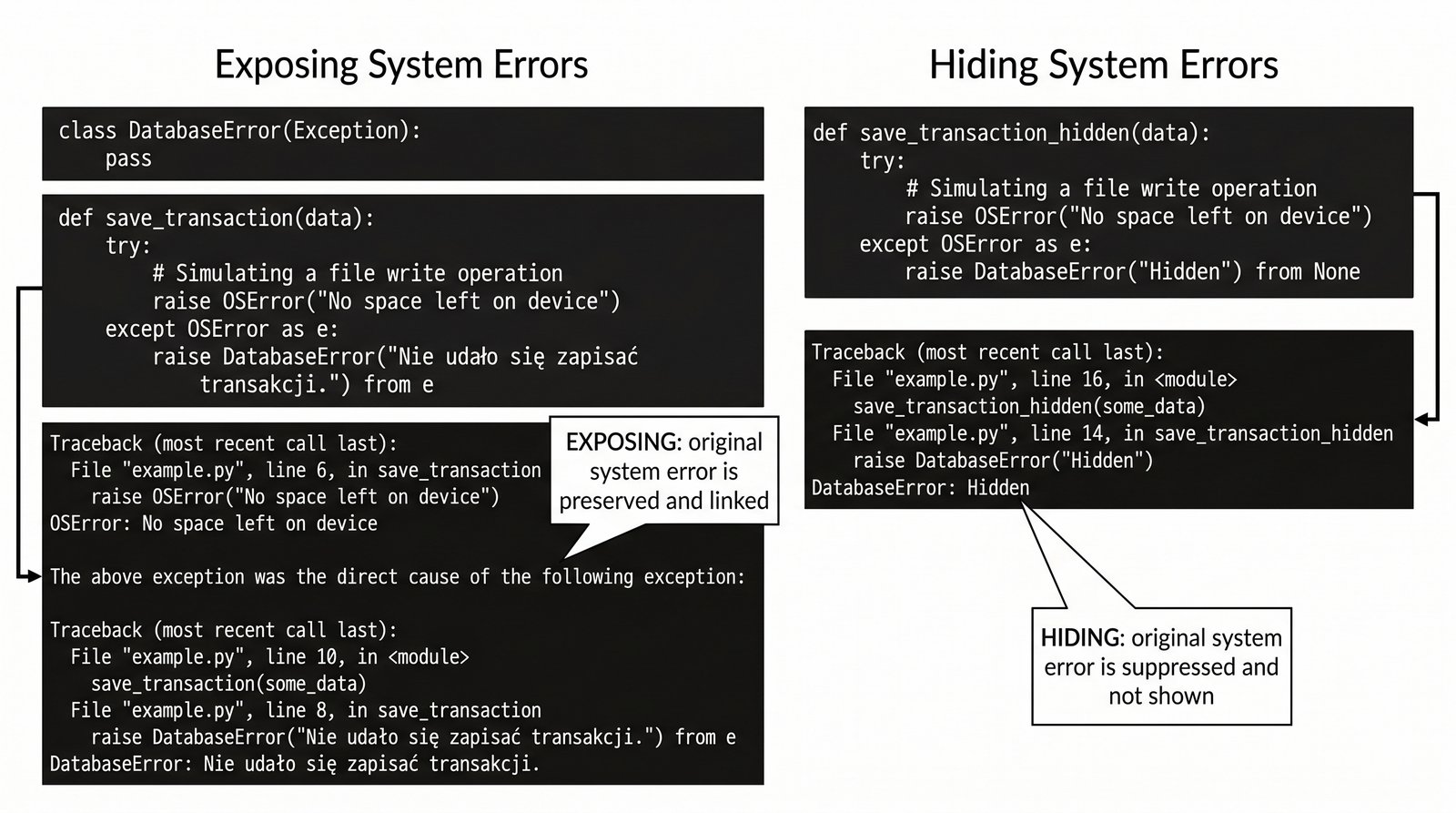
Podczas pracy z zaawansowanymi systemami bazodanowymi, błędy niskopoziomowe pochodzące z systemu operacyjnego mogą być trudne do zinterpretowania przez użytkownika końcowego Twojej aplikacji. Twoim celem jest stworzenie inteligentnego modułu zapisu danych, który potrafi mapować błędy fizyczne, takie jak brak miejsca na dysku, na czytelne komunikaty o błędach biznesowych. Wykorzystaj mechanizm łańcuchowania wyjątków raise from, aby stworzyć logiczne połączenie między Twoim własnym błędem DatabaseError a pierwotną przyczyną systemową. Dzięki temu programista analizujący logi będzie widział pełną historię zdarzeń, wiedząc dokładnie, dlaczego transakcja nie mogła zostać sfinalizowana. Jest to technika "security and transparency", która pozwala na zachowanie technicznych detali dla administratorów przy jednoczesnym prezentowaniu zrozumiałych informacji dla użytkowników. Musisz zadbać o to, aby nowo zgłaszany wyjątek dostarczał wszystkich niezbędnych kontekstów do poprawnej diagnozy problemu w przyszłości. Takie podejście jest standardem w profesjonalnych frameworkach, gdzie liczy się precyzja w namierzaniu źródeł awarii w rozproszonych środowiskach. Twoje rozwiązanie pokaże, jak elegancko łączyć różne warstwy abstrakcji błędów w jednym, spójnym mechanizmie raportowania. Gotowy system będzie stanowił solidną podstawę dla modułu trwałości danych w Twoim autorskim systemie zarządzania bazą dokumentów.
- Zdefiniuj własną klasę błędu wysokiego poziomu, np.
DatabaseError. - Zaimplementuj funkcję symulującą zapis do bazy danych, która może rzucić wyjątek systemowy
OSError. - Przechwyć błąd systemowy i zgłoś na jego podstawie
DatabaseError, używając składniraise ... from e. - Przeanalizuj wygenerowany Traceback, szukając komunikatu "The above exception was the direct cause...".
- Dodaj do obiektu
DatabaseErrorszczegółowe informacje o tym, która tabela lub operacja zawiodła. - Przetestuj wariant ukrywania przyczyny źródłowej za pomocą składni
raise ... from None. - Udowodnij, że łańcuchowanie wyjątków ułatwia analizę przyczyn awarii (Root Cause Analysis).
- Wyjaśnij, kiedy warto eksponować błąd systemowy, a kiedy lepiej go hermetyzować w błędzie biznesowym.
- Zdefiniuj autorską klasę błędu biznesowego wysokiego poziomu, np.
DatabaseError. - W funkcji
zapisz_dane()wywołaj operację mogącą rzucićOSError(np. zapis do folderu tylko do odczytu). - Wewnątrz
except OSError as e:zgłoś błądraise DatabaseError("Błąd bazy") from e. - Uruchom program i przeanalizuj pełny raport błędu – obie przyczyny powinny być widoczne i połączone.
- Przetestuj składnię
raise DatabaseError(...) from Nonei zaobserwuj, że pierwotny błądOSErrorzostał ukryty. - To zadanie uczy profesjonalnego zarządzania "historią" i przyczynowością błędów w złożonych systemach.
- Wyjaśnij pojęcie "hermetyzacji błędów" – dlaczego warto ukrywać detale techniczne przed końcowym użytkownikiem.
- Sprawdź, jak mechanizm
from epomaga Ci jako deweloperowi w szybkim namierzaniu pierwotnej przyczyny awarii. - Zastanów się, jakie techniczne detale błędów mogą stanowić zagrożenie bezpieczeństwa przy ich upublicznieniu.
- Udowodnij, że
raise fromjest znacznie lepszym podejściem niż zwykłeraiseprzy konwersji typów błędów.
- Wyjaśnij, kiedy i dlaczego warto ukrywać oryginalny błąd systemowy za pomocą składni
raise ... from Noneze względów bezpieczeństwa informacji. - Opisz mechanizm łańcuchowania wyjątków (
Exception Chaining) i jego kluczowy wpływ na profesjonalną analizę przyczyn źródłowych (RCA). - Omów znaczenie systemowego komunikatu "The above exception was the direct cause..." w szybkim debugowaniu złożonych aplikacji bazodanowych.
- Przeanalizuj, jakie techniczne detale błędów niskopoziomowych (np. ścieżki plików) mogą stanowić potencjalne zagrożenie dla bezpieczeństwa całego systemu.
- Zastanów się nad zaletami mapowania surowych błędów fizycznych (np.
OSError) na zrozumiałe i czytelne komunikaty biznesowe dla klienta końcowego. - Wnioskuj o poprawie jakości logów systemowych dzięki zachowaniu jawnych powiązań między różnymi warstwami abstrakcji zgłaszanych błędów.
- Porównaj nowoczesne podejście
raise fromdo ręcznego budowania komunikatów tekstowych zawierających opisy poprzednio wystąpionego błędu. - Opisz rolę hermetyzacji błędów w budowaniu stabilnych, profesjonalnych i bezpiecznych frameworków programistycznych.
- Sprawdź doświadczalnie, czy łańcuchowanie wyjątków działa poprawnie w przypadku wielokrotnego przekształcania typu błędu (łańcuch 3-stopniowy).
6. Grouping Exceptions
Jeśli kilka błędów wymaga tej samej reakcji, możesz je zgrupować w krotce: except (ValueError, TypeError):. Sprawia to, że kod jest bardziej zwięzły.
7. Hierarchia wyjątków
Wyjątki tworzą drzewo. Obsłużenie ArithmeticError automatycznie wyłapie również ZeroDivisionError i OverflowError. Zawsze staraj się być tak precyzyjny, jak to możliwe.
8. Instrukcja assert
Służy do sprawdzania warunków, które "zawsze muszą być prawdziwe". Jeśli assert zawiedzie, rzucany jest AssertionError. Używaj go do debugowania, a nie do walidacji danych od użytkownika.
9. Propagacja wyjątków
Jeśli błąd nie zostanie obsłużony wewnątrz funkcji, "wypada" on na zewnątrz do miejsca wywołania. Może tak wędrować aż do samej góry programu. Jeśli nikt go nie złapie – program zakończy się błędem.
10. Podsumowanie odporności
Dobry programista pisze kod, który nie tylko działa, gdy wszystko jest dobrze, ale przede wszystkim potrafi elegancko "przetrwać" błędy. Twoje aplikacje są teraz gotowe na starcie z rzeczywistością i nieprzewidywalnymi użytkownikami.
Łączenia wszystkich poznanych technik w jeden spójny system obsługi błędów w aplikacji obiektowej.
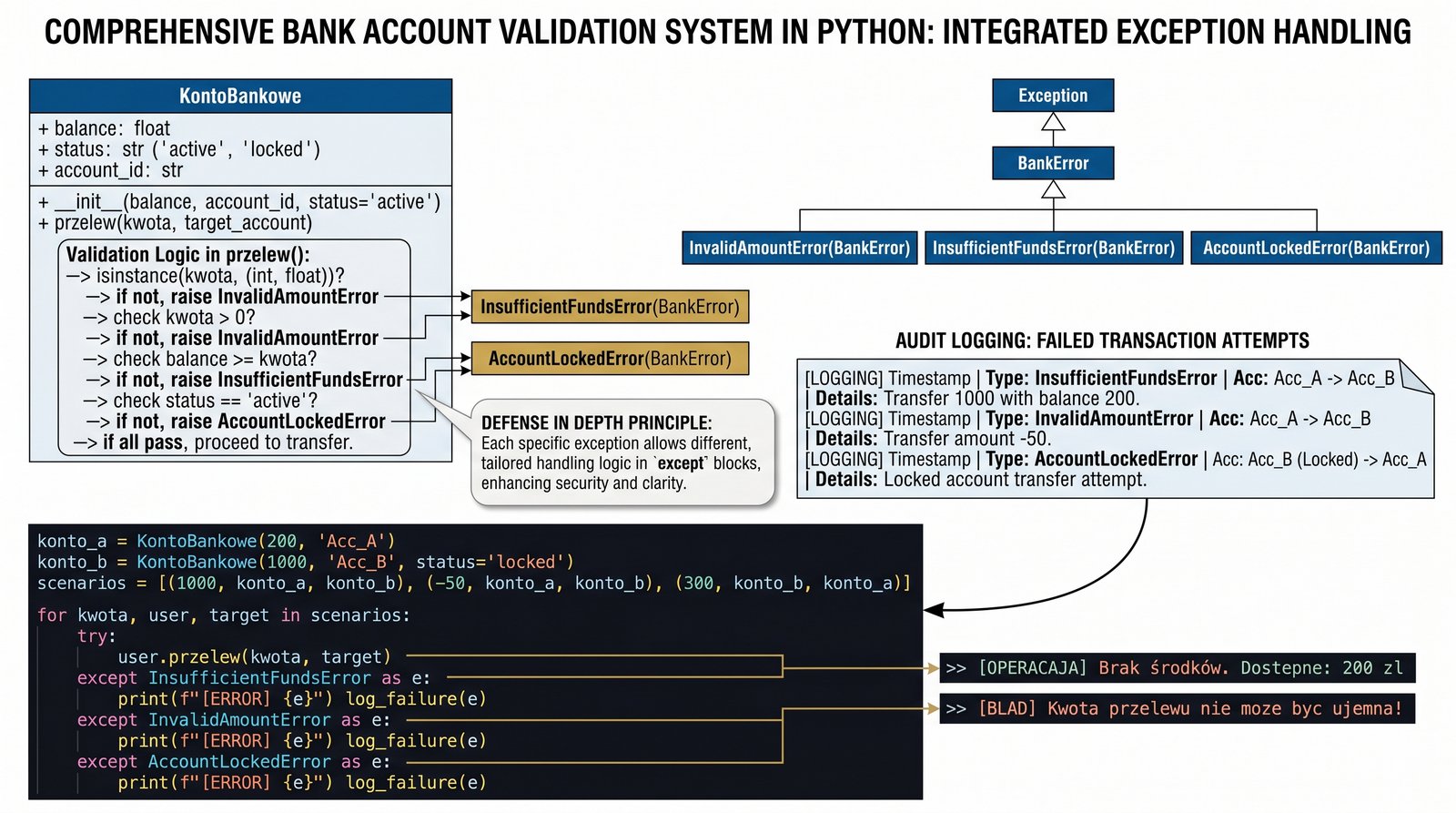
Końcowym wyzwaniem w tym module jest zaprojektowanie kompleksowego systemu walidacji dla zaawansowanej klasy konta bankowego, integrującego wszystkie poznane techniki obsługi błędów. Twoim zadaniem jest stworzenie mechanizmu przelewów, który rygorystycznie sprawdza warunki biznesowe i rzuca specyficzne wyjątki w sytuacjach naruszenia zasad bankowych. Musisz opracować hierarchię błędów, zaczynając od ogólnego typu BankError, po którym będą dziedziczyć bardziej szczegółowe klasy, takie jak te dotyczące ujemnych kwot czy zablokowanych rachunków. System powinien nie tylko blokować nieprawidłowe operacje, ale również logować każdą próbę nadużycia do celów audytowych przed przekazaniem informacji do interfejsu klienta. Napisz pętlę testową, która w sposób kontrolowany wywoła serię błędnych transakcji, demonstrując, jak program potrafi różnicować reakcje w zależności od rodzaju napotkanego problemu. Pamiętaj, że dla użytkownika informacja o braku środków wymaga innej reakcji niż błąd techniczny połączenia z serwerem, co musi znaleźć odzwierciedlenie w Twoim kodzie. Dzięki temu zadaniu nauczysz się projektować systemy o "wysokiej odporności", które potrafią przetrwać nawet najbardziej nieprzewidywalne scenariusze interakcji. Poprawna realizacja tego modułu będzie dowodem Twojego profesjonalizmu w tworzeniu bezpiecznego i przewidywalnego oprogramowania obiektowego.
- Zaprojektuj rozbudowaną hierarchię wyjątków bankowych z klasą bazową
BankError. - Skonstruuj podklasy takie jak
InvalidAmountError,InsufficientFundsErrororazAccountLockedError. - Zaimplementuj klasę
KontoBankowez rygorystyczną walidacją wszystkich parametrów wejściowych (np.isinstance). - Opracuj metodę przelewu, która rzuca odpowiednie typy wyjątków w zależności od napotkanych naruszeń zasad.
- Zaimplementuj system logowania błędów wewnątrz klasy, zanim zostaną one przekazane do obsługi zewnętrznej.
- Napisz pętlę testową, która wywołuje serię niepoprawnych transakcji i różnicuje reakcje w wielu blokach
except. - Wykorzystaj dane zawarte w wyjątkach do generowania precyzyjnych komunikatów dla klienta końcowego.
- Udowodnij skuteczność systemu poprzez przeprowadzenie "ataku" na klasę konta (niepoprawne typy, ujemne kwoty).
- Stwórz bazową klasę
BankError(Exception)i co najmniej trzy specjalistyczne podklasy błędów. - Metoda
przelew(self, kwota, cel)musi rygorystycznie sprawdzać wszystkie warunki poprawności operacji. - Sprawdź, czy kwota jest liczbą dodatnią, rzucając w razie błędu
InvalidAmountError. - Zweryfikuj, czy stan konta pozwala na transakcję, rzucając
InsufficientFundsErrorprzy braku środków. - Obsłuż stan blokady konta (atrybut
czy_aktywne), rzucającAccountLockedError. - W pętli testowej obsłuż każdy typ błędu w osobnym bloku
except, wyświetlając zindywidualizowane komunikaty. - Wykorzystaj instrukcję
assertdo weryfikacji stanów, które według logiki programu "nigdy nie powinny wystąpić". - To zadanie łączy zaawansowaną wiedzę o hierarchii klas z praktyczną obsługą wyjątków w logice biznesowej.
- Przetestuj odporność swojej klasy na złośliwe dane wejściowe, takie jak przekazanie tekstu zamiast wartości liczbowej.
- Wyjaśnij, dlaczego "połykanie" wyjątków (
except: pass) jest uważane za najgorszą praktykę w inżynierii oprogramowania.
- Wyjaśnij szczegółowo, dlaczego "połykanie" wyjątków (
except Exception: pass) jest uważane za jedną z najgorszych praktyk w profesjonalnej inżynierii oprogramowania. - Opisz zalety projektowania spójnej hierarchii wyjątków biznesowych z jedną wspólną klasą bazową dla całego modułu (np.
BankError). - Omów rolę instrukcji
assertw weryfikacji krytycznych stanów programu, które według logiki dewelopera nigdy nie powinny wystąpić w runtime. - Przeanalizuj różnice w reakcji systemu na błędy czysto techniczne (np. timeout połączenia) oraz błędy walidacji danych wejściowych (np. ujemna kwota).
- Zastanów się nad bezwzględną koniecznością logowania wszelkich prób nadużyć (np. próba przelewu z zablokowanego konta) do celów audytowych.
- Wnioskuj o budowaniu systemów o "wysokiej odporności" (resilience), które potrafią bezpiecznie przetrwać nawet najbardziej nieprzewidywalne scenariusze.
- Porównaj rygorystyczną walidację typów parametrów (
isinstance) do elastycznego podejścia "Duck Typing" w kontekście aplikacji bankowych. - Opisz proces tworzenia pętli testowych symulujących serie celowo niepoprawnych transakcji w celu rygorystycznej weryfikacji stabilności modułu.
- Sprawdź, czy Twój system poprawnie różnicuje komunikaty dla użytkownika końcowego w zależności od konkretnej podklasy błędu
BankError.