Wykład 8: Iteratory i Generatory
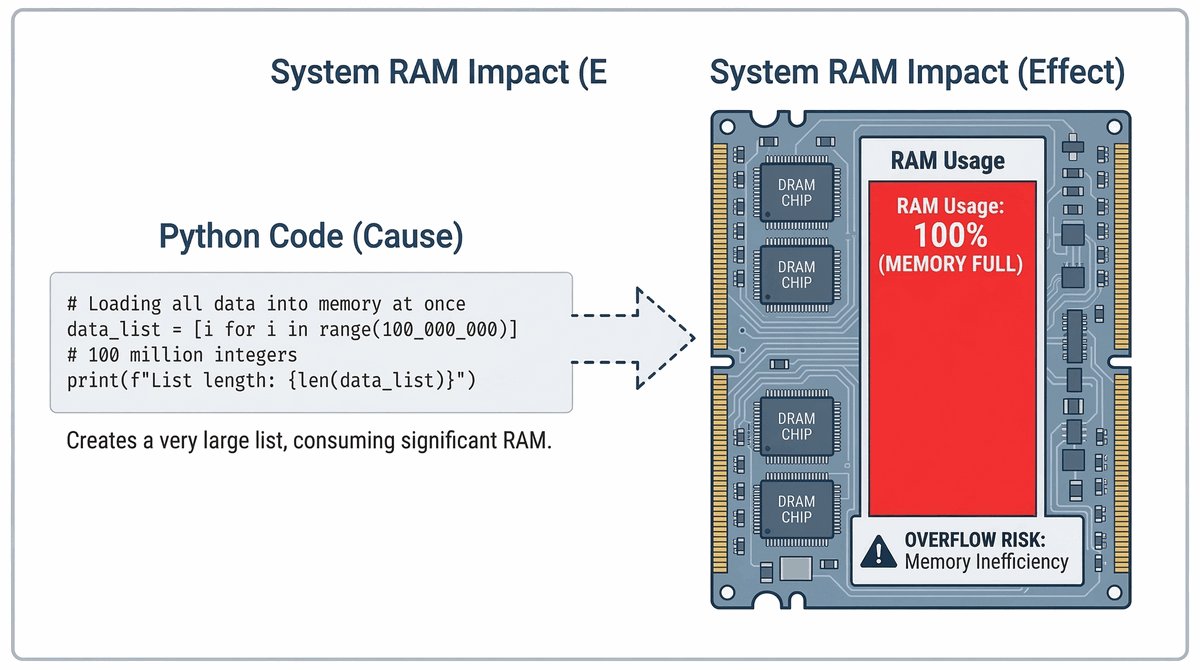
Jak efektywnie przetwarzać tysiące, a nawet miliony elementów nie zapychając pamięci RAM? Dlaczego pętla for w Pythonie jest tak potężna?
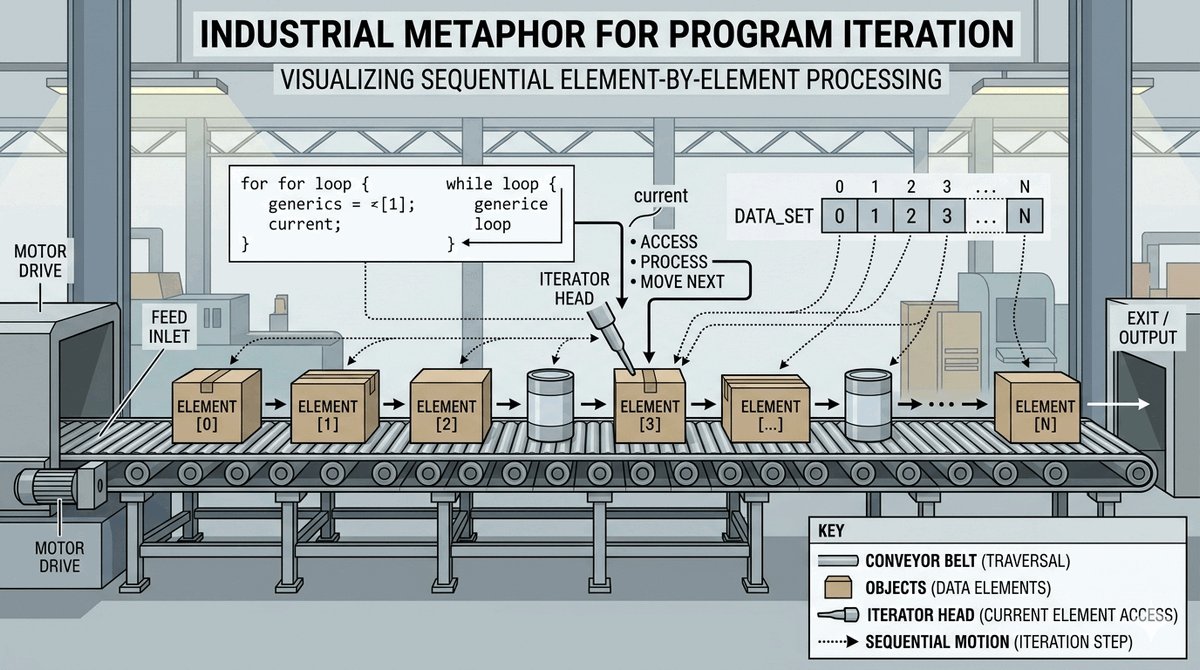
- Iteracja: Proces przechodzenia po elementach zbioru.
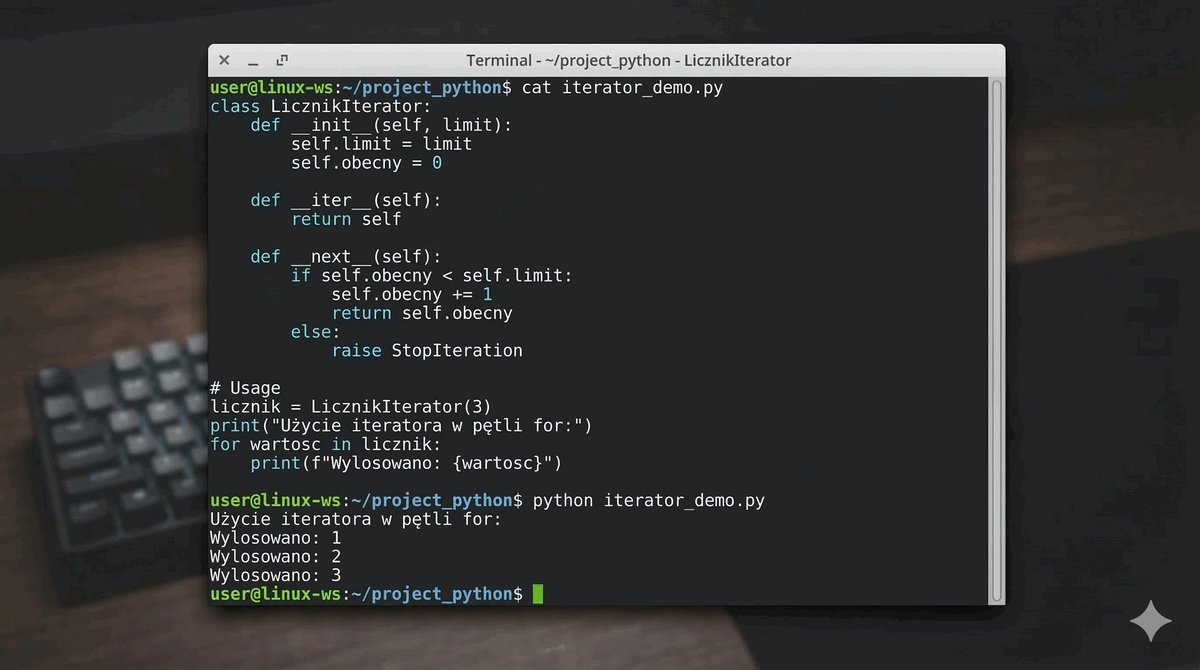
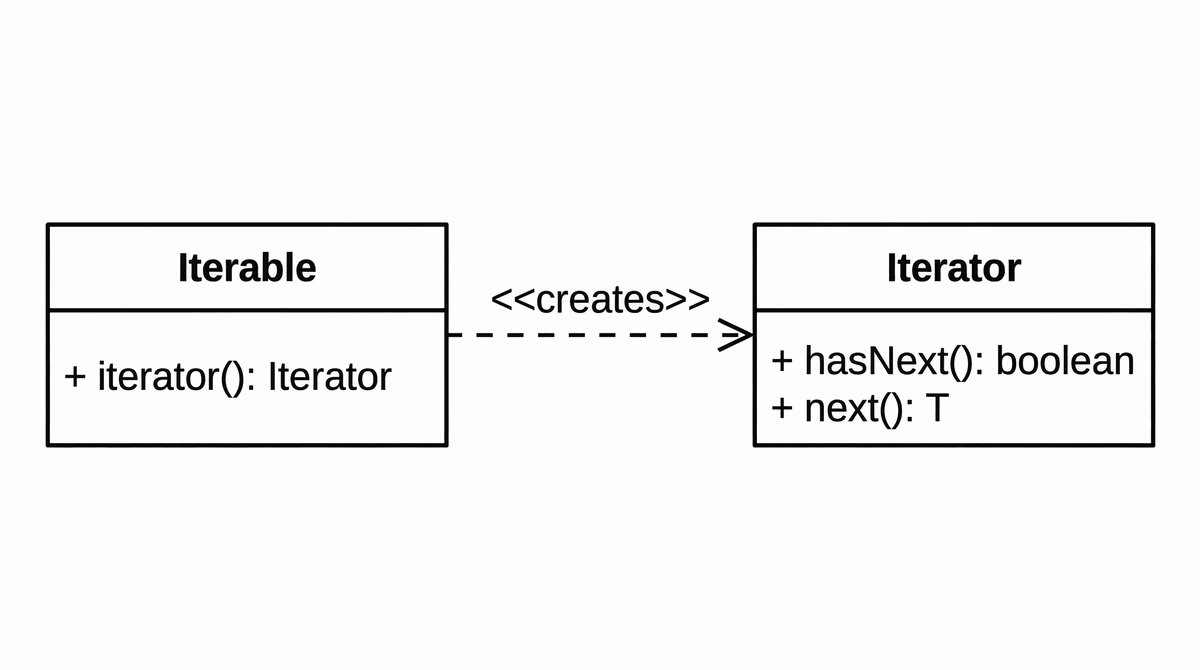
- Protokół Iteratora: Magiczne metody
__iter__i__next__. - Generatory: Funkcje, które "pamiętają" swój stan dzięki
yield. - Lazy Evaluation (leniwe wyliczanie): Leniwe wyliczanie wartości tylko wtedy, gdy są potrzebne.
- Wydajność: Oszczędność pamięci przy pracy z dużymi zbiorami danych.
- Generator Expressions: Szybkie tworzenie generatorów w jednej linii.
Co to jest iterator w Pythonie? Iterator to obiekt, który pozwala ci przechodzić przez elementy zbioru (jak lista czy plik) jeden po drugim. Zamiast trzymać wszystkie dane w pamięci na raz, iterator zwraca element tylko wtedy, gdy o niego poprosisz. Dzięki temu możesz przetwarzać miliony rekordów z pliku bezproblemowo.